So far this is the absolute record for the binary size of one division/remainder/multiplication operation:
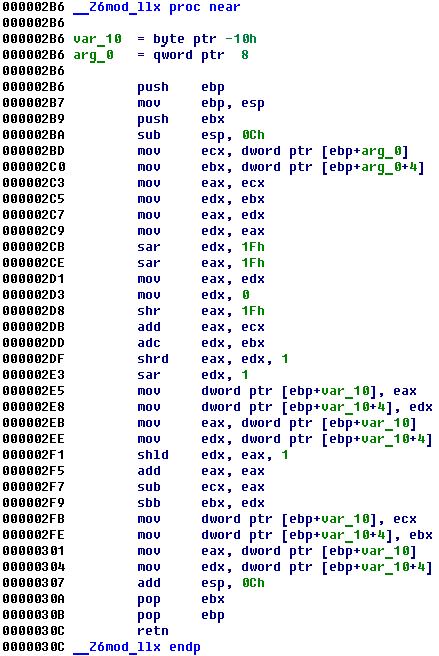
35 instructions, 87 bytes of code just to calculate a remainder of division by 2:
long long smod(long long x) { return x % 2; }
(compiled by gcc 3.4.4)
Anyone to come up with a longer single arithmeric operation?
